
For the past few weeks at the Recurse Center, I’ve been building a charity recommender system to help me understand testing, HTTP requests, and various other useful programming concepts. I’ve already discussed the Python testing frameworks I’ve explored in another blog post, but I promised to provide an explanation of the project itself. So, Athena, here goes! In this blog post I’ll discuss:
- What a recommender system is and what types of recommender systems exist
- A brief overview of how content-based recommender systems work
- How I implemented my toy content-based recommender system
We have to start with…what is a recommender system? My recommender system was based on recommending charities to people interested in donating, but the ideas and code apply equally well to, say, recommending cat food.† Suppose I knew a certain cat liked chicken-based cat food, and didn’t like pâté-style cat food. Suppose further that I had to choose between dozens of brands of cat food, each of which has dozens of flavors and textures, in order to find the best cat food for this cat. How would I ever find the right cat food?

I could just randomly choose a brand and flavor of cat food, but that doesn’t account very well for the information I already have about what the cat likes and doesn’t like. A recommender system is a program that keeps track of the cat’s likes and dislikes, and recommends cat food brands and flavors based on those preferences.
There are two major kinds of recommender systems: content-based recommender systems and collaborative filtering recommender systems. A content-based recommender system would only recommend cat food based on what qualities the cat liked and didn’t like in a cat food. A collaborative filtering recommender system would recommend cat food based on what cat foods were popular among other cats with similar cat food preferences. Content-based recommender systems tend to be ideal when you don’t have data about the preferences of a user base. Collaborative filtering recommender systems incorporate an item’s popularity into their final recommendations, so they really require a lot of users in order to be effective.
I implemented a content-based recommender system, so let’s talk about how that works. Let’s use this tiny example database of cat food.

One way to analyze a database like this is to create a “feature vector” for every type of cat food. (If you’re not familiar with vectors, here’s a quick refresher.) This vector would be composed of numerical quantities describing each category the cat food could fall into. To turn our categories of protein into numerical quantities, for instance, we might create four separate vectors to describe each of the types of protein used in cat food. We would have a vector describing how “chicken-y” the cat food is, where the “Chicken” feature would equal 1 if there were chicken in the cat food and 0 if there weren’t. We would repeat this for each of the possible protein options, and for each of our other categories, producing a database as shown.

Now that we have a nice way to describe our data, we would also need to create a user profile in the same format. Remember how the cat in our example likes chicken, and does not like a pâté-style texture? We would then make sure that the vector describing our user has a 1 in the “Chicken” feature and a 0 in the “Pate(y/n)” feature.††
We next need a way to compare how similar the user’s preference is to each cat food option in our database. Let’s visualize this:
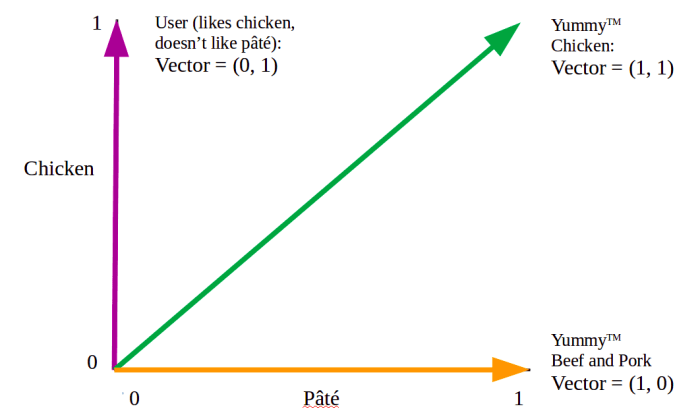
The cat’s preference vector is in purple, the leftmost vector on the graph. There are two possible cat food options, the vectors in green and orange in the middle and on the bottom, respectively. When we look at the angles between the vectors, it is straightforward to see that the angle between the user preference vector and the Yummy™ Chicken vector is smaller than the angle between the user and the Yummy™ Beef and Pork vector. This makes sense; we already know the cat likes chicken, so we expect the vector describing the chicken cat food to be closer to the cat’s preference than a vector describing a cat food with no chicken.
The way I chose to mathematically encode this intuition is with the cosine distance, which is essentially a way of measuring the angle between two vectors. The mathematical relationship is expressed as
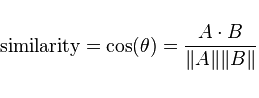
The numerator of this expression is the dot product of the two vectors, and the denominator multiplies the magnitudes of each of the vectors. The result is a measure of the distance between the vectors. After we have calculated the similarity, we will repeat this process with every cat food in the database, determining how similar it is to the user’s preferences.
Here’s the code I used to implement this idea.
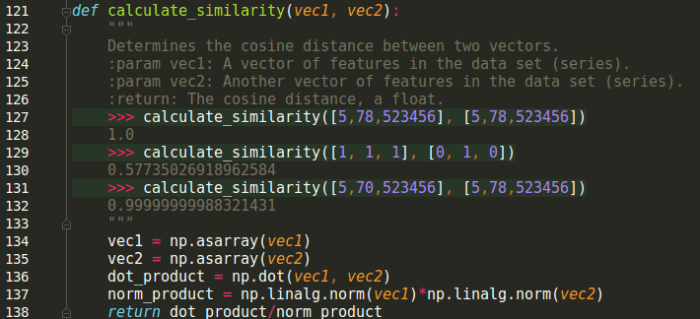
Finally, once we have calculated all the similarities, we choose the cat food that is most similar to the user’s preferences and recommend that cat food to our chicken-loving, pâté-hating feline friend.
To take a closer look at how this sort of problem might be implemented, here’s a link to my first-draft charity recommender. So far, I haven’t built a recommender system that handles large datasets, nor have I decided how to pick the categories to use in my model’s feature vectors. Those ideas will be implemented in a future version of the project (unless I get distracted by a different project!)

† Athena, I should point out that while all my examples here are based on cat food, I originally wrote the recommender system to deal with charities! With that in mind, I consider it appropriate to include a shout-out to Lapcats, an organization that matches cats to adopt with humans who want to adopt them, and from which I adopted you! So Athena, if you happen to have a cash stream I don’t know about, you might consider directing some of it toward the organization that rescued you from a bad situation and brought you to my (very educational) adoptive care 🙂
†† You may be wondering: what do we do if the cat has no preference in a certain category – say, the cat might not have a preferred brand of food? That’s a great and difficult question to answer. For this example, I will give the cat’s user vector a 0.5 in each of the brand categories. I will also assign 0.5 to each of the protein options besides chicken, since knowing the cat likes chicken doesn’t tell us anything about whether the cat likes beef. But making a guess about the user’s preference without much initial information can be quite hard – it’s sometimes referred to as the “cold start” problem.
