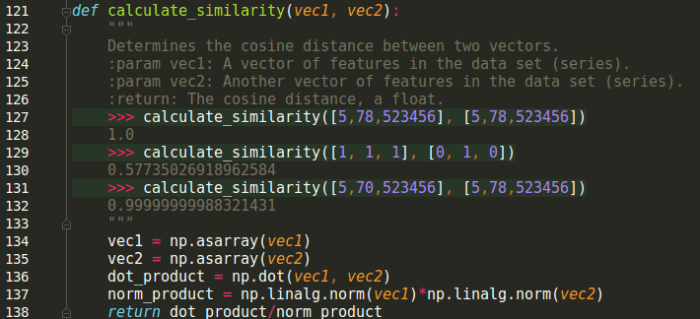
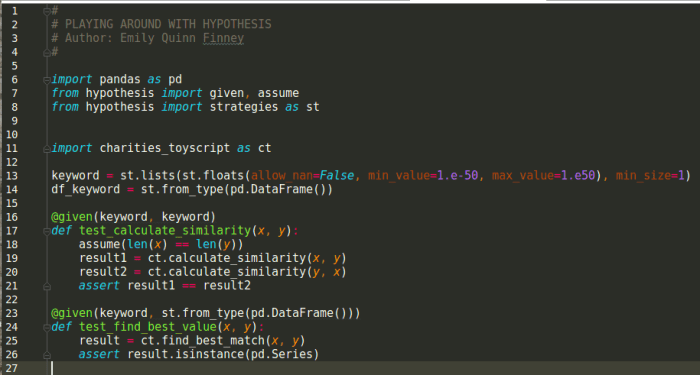
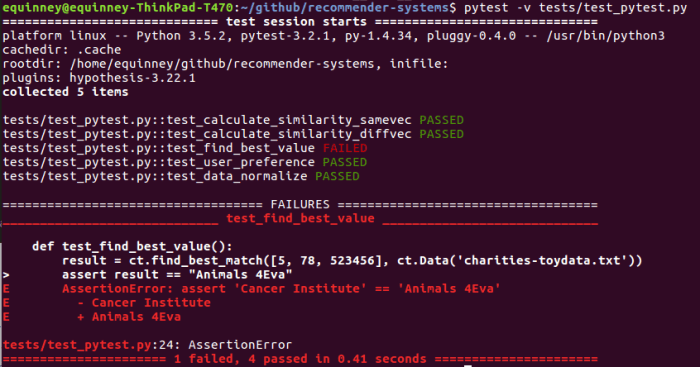
Hello Athena! It’s been an awfully long time since I’ve posted new educational content for you – sorry about that. I found it to be surprisingly difficult to keep up with writing and projects while interviewing for jobs. But – hooray! – I’ve recently been hired as a software engineer at Wise.io/General Electric to integrate machine learning models into our customers’ businesses. You won’t be hearing many specifics about those projects – GE has trade secrets and all that – but I plan to keep sharing the basics of what I’m learning along the way.
This blog post, though, is a reflection on my interview process: what happened, what I looked for in a team, what kinds of interviews discouraged me, positive interview experiences that kept me going, and what I’ve learned from the whole deal. I particularly want to emphasize how the structure of different kinds of interviews affected me as a female junior engineer. Plenty of companies are looking to hire great talent, and plenty of talented female junior engineers are looking to get hired. I hope the ideas in this post are helpful to both of those groups.
The Statistics†
Engineering interviews are pretty involved. There are usually at least four stages: a resume screen, a phone call with a recruiter or manager, a technical phone interview, and an onsite comprised of 4-6 interviews. Some companies give a take-home assignment instead of or in addition to a technical phone interview.
Many companies rejected my application outright because they wanted to hire senior engineers. That said, I found companies were MUCH more likely to be interested in my application (e.g., contact me for an interview) if I was referred by an employee or by the Recurse Center jobs team.
| Type of application | # Interested | % Interested |
|---|---|---|
| Online | 1 / 9 | 11.1 % |
| Referral | 13 / 34 | 38.2 % |
| Total | 14 / 43 | 32.6 % |
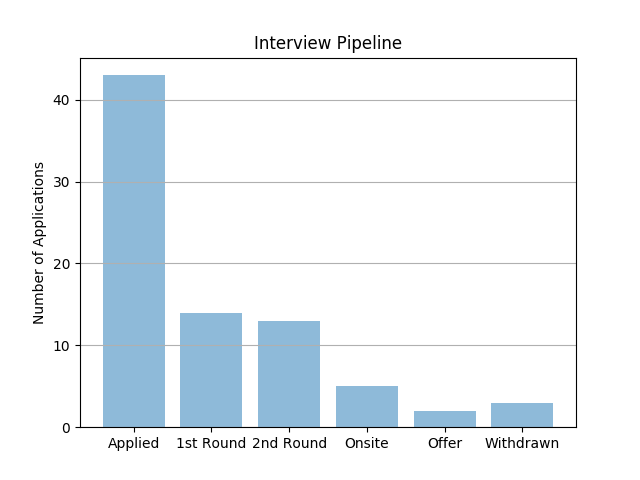
There were a lot of reasons interviews didn’t work out, some of which had to do with how I stacked up to a company’s interview standards, and some of which had nothing to do with my interview performance (e.g., company had moved forward with someone else, or realized mid-process that they wanted someone more senior).
Evaluating The Interviewers
Interviews are a two-way street. I asked a lot of questions of my interviewers! This gave me an opportunity to connect with my interviewers as people (after all, they’re potential co-workers) and also to get a sense of the company itself.
For me, it is very important to work in a collaborative, growth-oriented environment, so I spent a while trying to make sure that each company I interviewed with was a good fit. When a job posting described an ideal employee as being a “rock star” or “code ninja”, or if the listing required a large number of years of experience (4+) for a job description that seemed fairly entry-level, that suggested to me that the company might be individualistic or uninterested in helping employees grow into the role.
Similarly, when I interviewed and asked about opportunities for continuing education (conferences etc.), I looked for an enthusiastic response with specific details about how the company fostered employee learning. A tepid response suggested to me that growth may not be an important part of the organization (worse was when the interviewer was confused by the very premise of a desire to learn).
Of course, these signals aren’t always reliable – there were lots of times I chose to be flexible on some of these specifics based on more reliable information such as the recommendation of a close friend. Some of my initial reactions turned out to be unfair, so try to find people who are as close to the position as possible. And during the question-asking, stay as positive as possible so you convey enthusiasm to your interviewer, even as you’re vetting what they say about their organization.
The Hard Stuff
I put a lot of time and thought into understanding the companies at which I was interviewing. Similarly, companies rely on certain signals from their candidates in order to make a hire, presumably to ensure that the candidate is a well-adjusted and technically competent worker.
In my experience, though, some interviews tended to rely on signals that may not have much to do with aptitude, and that could especially negatively affect junior or minority candidates. For instance, I sometimes encountered interviewers that judged candidates primarily on code speed. Companies that do this may reject a good candidate who is nervous, or worse, implicitly penalize clear communication. In a pretty good article about best hiring practices, Marco Rogers, engineering lead and hiring manager for Lever, describes another example of this problem:
“No matter how repeatable and standardized your interview process gets, it’s driven forward by humans — and with that comes judgment and bias…For example, some engineers discount candidates if they don’t name their variables well in a technical exercise. The truth is that’s really common. So it’s important to level: ‘Is naming variables well in code really an important thing? Yes, it is. Is it a really coachable and fixable thing? Yes that’s true. So it shouldn’t disqualify people. That’s why we do code reviews. We teach this.’”
All that to say, it’s important for interviewers to check their biases. Especially among junior candidates, unfamiliarity with certain terms, poor variable naming, or code speed may be stronger signals of confidence or experience than of coding ability.
Other companies didn’t seem to think through the interview process at all. I sometimes hear stories of people getting rejected from jobs after they failed to solve an NP-complete problem in polynomial time. While I didn’t run into that specific situation, I did run into interviewers who expected me to produce a very specific solution and penalized anything outside their expectations. This tendency served to diminish my creativity in the interview process, and on the hiring end, would make it hard to determine how a candidate thinks about a new problem.
The Good Stuff
On the other hand, I found even small changes to an interview process could make it much more friendly, and produce more reliable signals! In this section, I’ll describe some of the specific measures interviewers took that helped me present at my best.
One of the most helpful things an interviewer could do to make an interview better was to build trust at the very beginning of the interview. Interviewing is a very vulnerable experience, so interviews that directly and proactively addressed my nervousness with kind assurances were very refreshing. Examples of kind assurances:
- “Feel free to take your time solving this problem.”
- “This interview is mostly about understanding how you think, so don’t worry about getting every detail right.”
- “I’m excited to see how you approach this.”
In some sense, it was weird that these assurances worked – no matter what the interviewer says, you’re still going to be accepted or rejected based on their evaluation of your interview performance – but they did help me feel like the interviewer saw me as a person and not just as a candidate. This made me less nervous, and more likely to code at my best.
I also appreciated companies that structured the interview process to learn something new or to let candidates choose how to show off their skills. One interviewer gave me a choice between an “easier” and a “harder” interview question, and assured me that which one I chose had no impact on his evaluation (it helped me relax so much that I ended up solving both). Another team asked me to give a technical talk in a field in which I’d excelled. A few companies carefully structured interview problems to start easy and give the me lots of room to go deep in understanding them. These interviewers tended to respond enthusiastically or compassionately when I said I didn’t know how to do something, a clear signal that the team valued learning and growth.
Finally, some companies were very explicit in emphasizing non-technical skills/attributes and emotional intelligence just as much as coding ability. One hiring manager made it clear he’d rather hire a less competent but emotionally mature person than a “brilliant asshole”. A few companies spent large parts of the interview asking me about my learning style or about something interesting I’d explored in the past month. These interview elements assured me that a company was evaluating me as a whole person rather than just as a “code ninja”.
To be clear, I did not pass all these interviews! My pass rate for interviews I liked vs. interviews I didn’t was actually about the same. But nearly all the companies with friendly interviews also seemed like places I’d be really happy to work. I don’t think it’s a coincidence that the companies putting thought into an empathetic interview process left a good impression on me 🙂
Takeaways
Interviewing wasn’t my favorite process, but it did give me lots of things to think about, either when I’m looking for a new job or when I’m the person interviewing a candidate.
For interviewees:
- Acknowledge that the person interviewing you is a real human with real feelings. Connecting with them as a person will probably make them feel more comfortable, and will give you more information about whether their company is a good fit for you.
- Interviewing is wild and lots of places reject you for lots of reasons. Don’t take it too personally. Improve in the areas you can, and don’t worry too much if you get rejected for thing that are unreasonable or beyond your control.
For interviewers:
- Acknowledge that the person you’re interviewing is a real human with real feelings. Connecting with them as a person will probably make them feel more comfortable, and will give you more information about whether they’re a good fit for your company.
- Good interviews make your company a more desirable place to work, so put thought into the process. Questions that help people learn or that give them a way to show off their skills will help you see what they’re capable of doing.
So keep this in mind, Athena, next time you’re interviewing. But given how you’re currently occupied, I suspect you won’t have to worry about this for a while.

† This section of the blog post is heavily inspired by Harold Treen’s interview reflection, and its format is used with his permission.





























 😀
😀